lxc.apparmor.profile: unconfined lxc.cgroup.devices.allow: a lxc.cap.drop: lxc.mount.auto: "proc:rw sys:rw"
创建开机脚本rc.local
1 2 3 4 5 6 7 8 9 10
#!/bin/sh -e
# Kubeadm 1.15 needs /dev/kmsg to be there, but it's not in lxc, but we can just use /dev/console instead # see: https://github.com/kubernetes-sigs/kind/issues/662 if [ ! -e /dev/kmsg ]; then ln -s /dev/console /dev/kmsg fi # https://medium.com/@kvaps/run-kubernetes-in-lxc-container-f04aa94b6c9c mount --make-rshared /
A tool which could get the dirpath of a function method’s caller
1
npm install caller-dir
Usually, if you want to get the current path, you can use __dirname in Nodejs, if you want to get the caller’s dirpath, you can call the function with a parameter which is __dirname, but it’s not graceful.
Now you can use this little tool caller-dir to get the caller’s dirpath gracefully.
var exec = require('child_process').exec; var spawn = require('child_process').spawn;
var gitEmail = spawn('git', ['config', 'user.email']); gitEmail.stdout.on('data', function (data) { var email = firstLineFromBuffer(data); var commitMsgFile = process.argv[2];
fs.readFile( commitMsgFile, function (err, buffer) { var message = firstLineFromBuffer(buffer);
// 公钥 var FD_f1342fFDFdsaf = 'MIGfMA0GCSqGSIb3DQfdsafdsafdsDCBiQKBgQDkAh06uqqrA8qIsyd98/E1p4oL0GAzUifdsafdsaOZpCwAdrh+I77Ws14u2UJWz4cBNnZBnS5hX/kWeUizGkPbW2AfdsafdsakuFfdsafdsanTJUQIDAQAB'; var encrypt = newJSEncrypt(); encrypt.setPublicKey(FD_f1342fFDFdsaf); returnfunction(opt) { var form = this; var beforeSubmit = opt.beforeSubmit; opt.beforeSubmit = function(fields) { var result = beforeSubmit && beforeSubmit.apply(this, arguments);
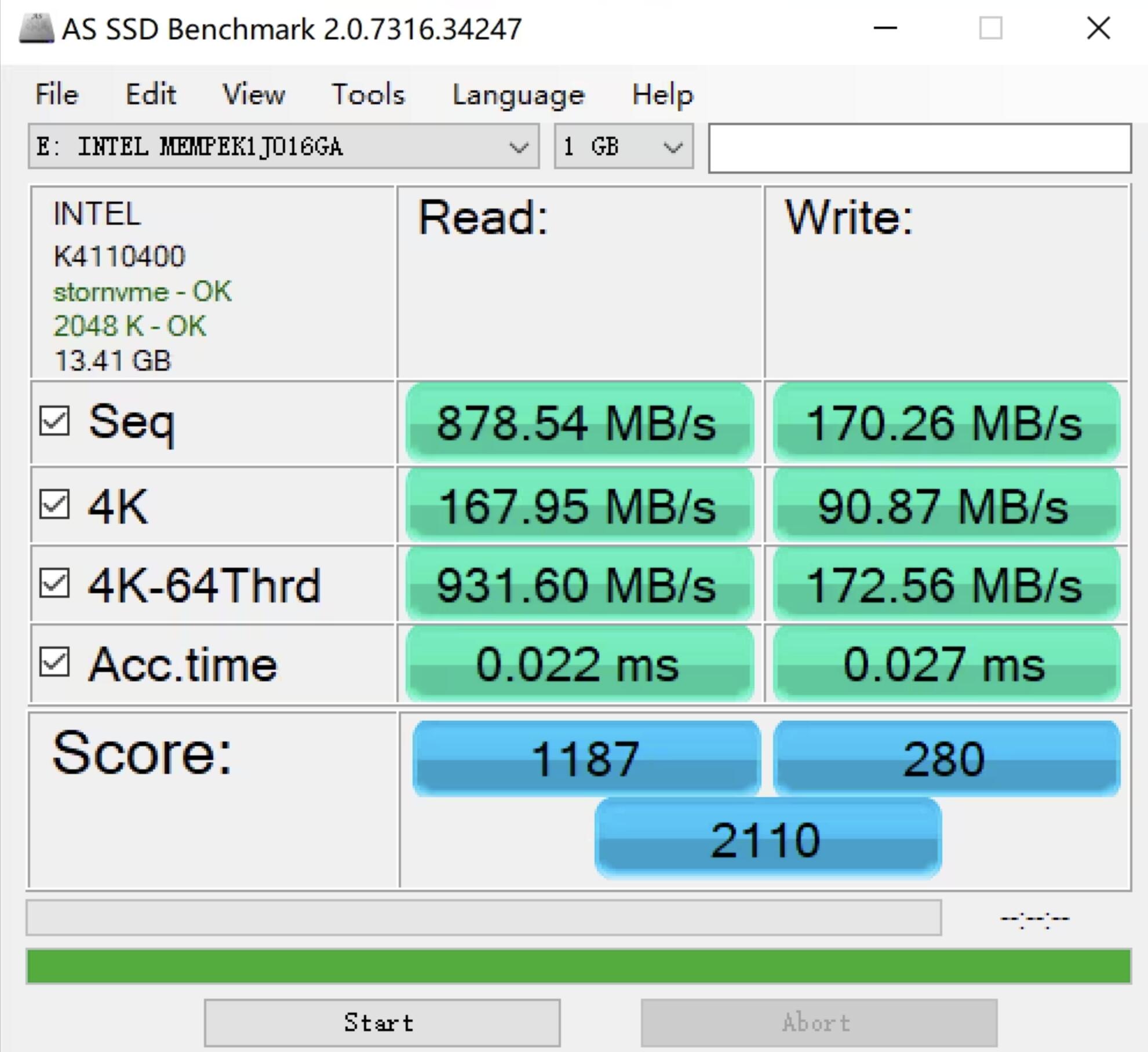
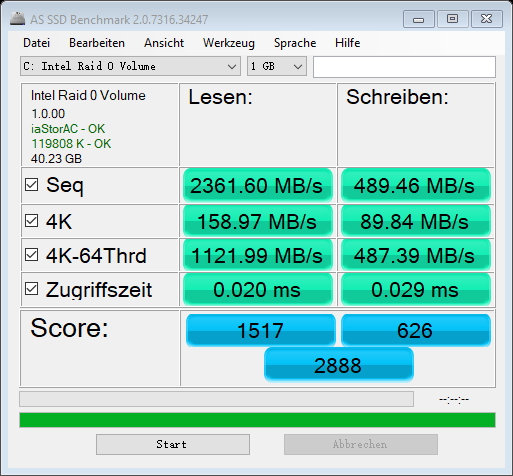




















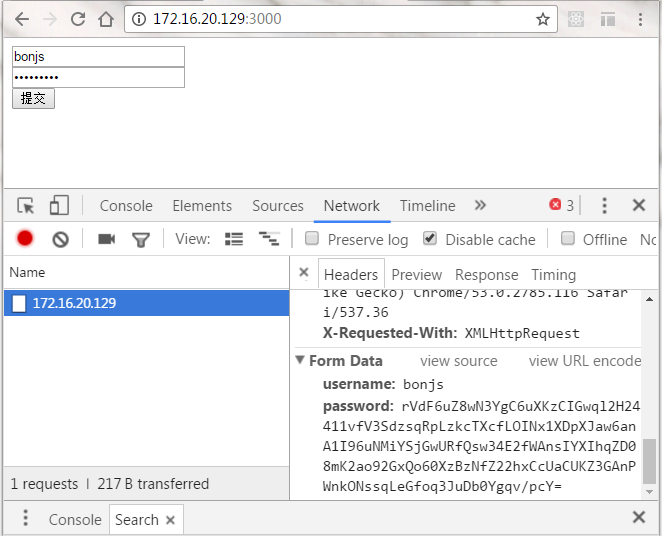
 要知道在以前的chrome版本中,此项功能是作为实验性功能出现在chrome中的,默认是关闭状态,需要手动打开才行,而现在默认就支持
要知道在以前的chrome版本中,此项功能是作为实验性功能出现在chrome中的,默认是关闭状态,需要手动打开才行,而现在默认就支持



























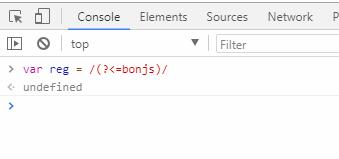
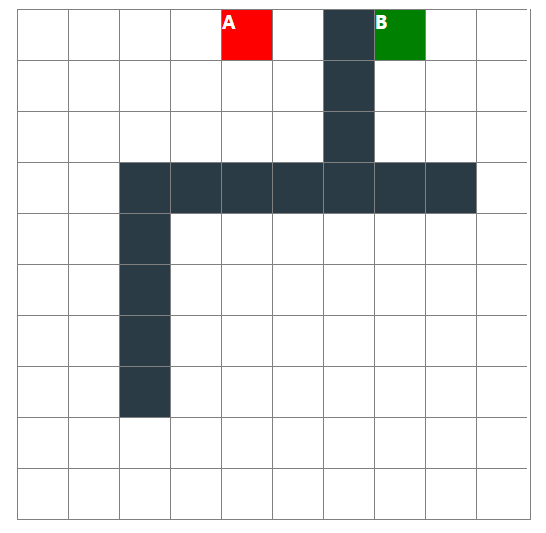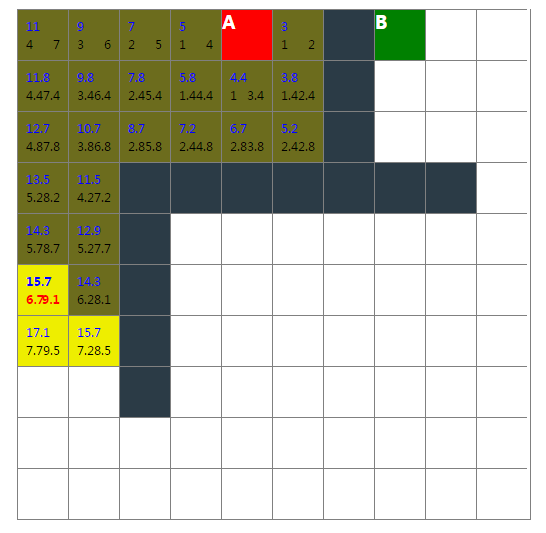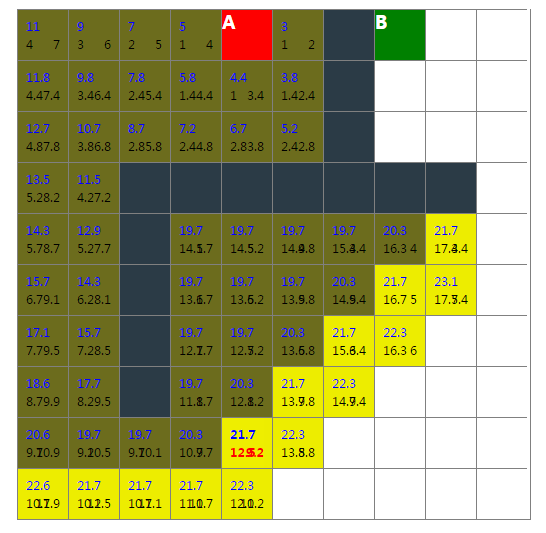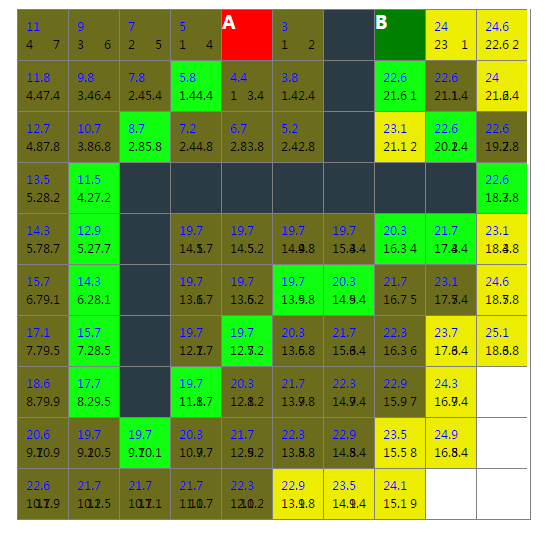 展示地址:http://bonjs.github.io/wayFinding
源码:https://github.com/bonjs/wayFinding.git
展示地址:http://bonjs.github.io/wayFinding
源码:https://github.com/bonjs/wayFinding.git
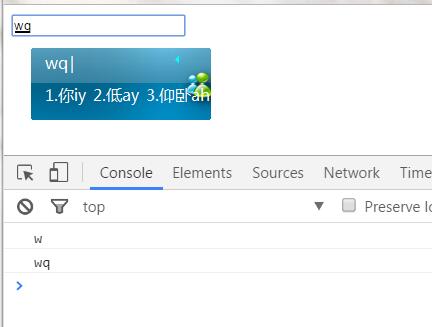

 那就改改吧, 这还能难的倒哥吗?
那就改改吧, 这还能难的倒哥吗?

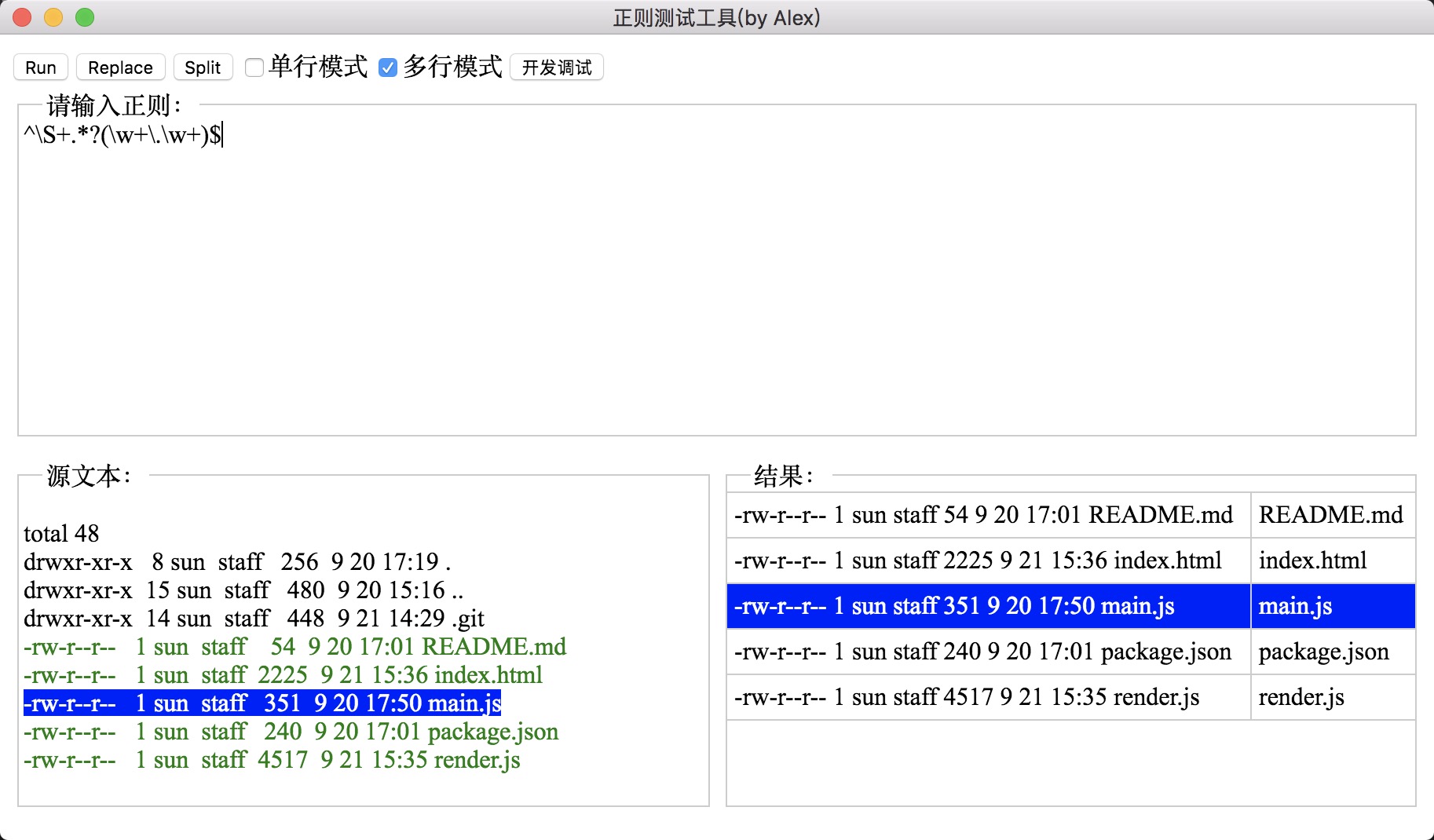
 果然啊, 捕获性分组还是非捕获性分组居然影响到了split的结果.. ,要知道在其他用法中, 如match, exec, test, 在这些用法中, 分组是捕获性还是非捕获性是不会影响到结果的,只是用来取值用的, 但在split中却影响匹配结果!
果然啊, 捕获性分组还是非捕获性分组居然影响到了split的结果.. ,要知道在其他用法中, 如match, exec, test, 在这些用法中, 分组是捕获性还是非捕获性是不会影响到结果的,只是用来取值用的, 但在split中却影响匹配结果!